
一、 MySQL FULLTEXT
1. 介绍: Fulltext是全文索引,mysql支持英文的全文索引(通过寻找某些分隔符来确定单词的起 始位置和结束位置),是mysql的一部分,如果需要建立中文的全文索引需要安装插件。
2. 使用:
CREATE TABLE 时或之后使用 ALTER TABLE 或 CREATE INDEX 在 CHAR、VARCHAR 或 TEXT 列上创建。全文搜索时通过 MATCH() 函数完成。
3. 优点: Mysql自带,实现简单
4. 缺点: 仅支持MyISAM引擎表;对中文支持差;效率可能一般;
5. 参考:
MySQL 英文全文搜索和中文全文搜索
MySQL Ver5.1全文搜索官方手册
6. 补充: 如果是英语系,可以考虑直接使用?
7. 加分词插件?
>> 我们用的Innodb存储引擎,排除。
二、 Lucene/Solr
1. 介绍:Lucene是一套用于和的,近几年最受欢迎的免费Java资讯 检索程式库。 - 使用Lucene的企业搜索服务器。
2. 使用:安装jdk, tomcat等环境;
3. 优点:开箱即用;对任何文件建立索引进行搜索,速度快; 使用的人多;配置等比较灵活;
4. 缺点:实现比较复杂, 不支持JAVA以外的API?;索引难维护;
5. 参考:
6. 推荐书籍:《Lucene IN ACTION》
>> 该方案需要JAVA同事搭建一个通用的搜索引擎,并提供接口。 看项目整体架构设计了。
三、 Sphinx(SQL Phrase Index)/ Coreseek/SphinxSE
1. 介绍:Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。Sphinx特别为一些脚本语言设计搜索API接口,如PHP,Python,Perl,Ruby等,同时为MySQL也设计了一个存储引擎插件。
Coreseek是Sphinx的本地化版本,开源的中文检索/搜索引擎。
SphinxSE是一个可以编译进MySQL 5.x版本的MySQL存储引擎,它利用了该版本MySQL的插件式体系结构。它其实是一个允许MySQL服务器与searchd交互并获取搜索结果的嵌入式客户端。所有的索引和搜索都发生在MySQL之外。 显然,SphinxSE的适用于: 使将MySQL FTS 应用程序移植到Sphinx; 使没有Sphinx API的那些语言也可以使用Sphinx; 当需要在MySQL端对Sphinx结果集做额外处理(例如对原始文档表做JOIN,MySQL端的额外过滤等等)时提供优化。
2. 使用:网上文档和资料很多。
3. 优点:开发源码为C/C++; 对MYSQL, POSTGRES集成的非常好, 支持原生的 mysql/xml/python等数据源;应用的人多;性能还不错;
4. 缺点:索引的实时更新不如lucene(新版有提高);功能不如lucene强大;
SphinxSE需要对Mysql源码重编译;
5. 参考:
Coreseek官网
Sphinx+Mysql+中文分词安装-实现中文全文搜索
与lucene、MySQL's full-text search的比较
推荐: by 张宴
>> 可以考虑,已安装测试中。
四、 Xunsearch
1.
2. 只提供PHP的API,不考虑。主要为hightman(scws中文分词作者)个人开发贡献。
3. 比较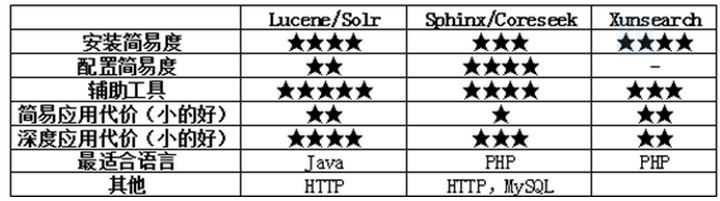
>> PHP专属,不考虑。
五、 Clucene
1. 介绍:C++版的全文检索引擎,完全移植于Lucene(通过修改Java的代码改编),采用 STL 编写。有php扩展,对中文支持不是很好。
2. 缺点:比较非主流..; 若干年未更新,使用人很少;
3. 参考: 源码
api文档
>> 没更新,没人用,不考虑。
六、 Xapian
1. 介绍:Xapian是一个用C++编写的全文检索程序,他的作用类似于Java的lucene。尽管在Java世界lucene已经是标准的全文检索程序,但是C/C++世界并没有相应的工具,而Xapian则填补了这个缺憾。
2. 使用:一个优秀的开源搜索引擎项目。上述xunsearch的后台索引设计就是基于Xapian和 scws中文分词。
3. 优点:原生的C++编程接口;性能和Lucene不会差太多;可扩展性强;
4. 缺点:工程大,资料少; 应用人群少;主要是怕短期搞不定。。;
5. 参考:
利用Xapian构建自己的搜索引擎:
>> 短期难度大,需投入较多人力研究和验证, 暂不考虑。
//==============================网友评论摘录 Lucene VS Sphinx =======================
选择Lucene,基于以下几点:1.Sphinx和MySQL是基于数据库的全文引擎,创建索引是B+树和hash key-value的方式。而Lucene使用的倒排序索引,即每个词与包含这个词的文件形成对应关系。这样对于搜索文档,显然倒排序索引快。2.Lucene除了索引功能,还提供文件格式识别(并建立索引)、分词(以前用的版本只有英文、德文等欧洲的语言)、评分算法(依据此结果排序)、多种搜索方式(组合、模糊、正则等)、搜索词高亮显示等诸多功能。3.为C/S和B/S方式分别提供支持。4.Lucene提供多种语言开发的版本,如:C++、Java、C#、Ruby、Python等。 ???5.提供扩展接口,方便功能扩展。
选择sphinx :
支持高速建立索引(可达10MB/秒,而Lucene建立索引的速度是1.8MB/秒)
高性能搜索(在2-4 GB的文本上搜索,平均0.1秒内获得结果)高扩展性(实测最高可对100GB的文本建立索引,单一索引可包含1亿条记录)支持分布式检索支持基于短语和基于统计的复合结果排序机制支持任意数量的文件字段(数值属性或全文检索属性)支持不同的搜索模式(“完全匹配”,“短语匹配”和“任一匹配”)支持作为Mysql的存储引擎(可以只改变sql就能实现全文搜索)coreseek就是基于sphinx实现的开源中文检索引擎
如果是用php作服务器端脚本,最好还是用sphinx。如果用java做服务器端脚本,lucene。sphinx相比lucene,配置简单,易用,功能没有lucene完善和强大。【服务端用C++的比较纠结 .. 】
